MySQL高频问点分类
1. 基础核心
整体架构、核心组件、存储引擎
2. 索引
各种树、索引的作用、常见索引类型、聚簇索引与非聚簇索引的区别、联合索引的最左前缀原则、索引的维护成本、回表查询与索引覆盖、如何合理使用索引、索引失效场景、explain执行计划分析
3. SQL语法与查询优化
复杂查询(子查询、join的内外连接、group by/having、limit分页)的执行逻辑、子查询与join性能对比及适用场景、order by 的排序原理、慢查询的定位与分析、复杂SQL的拆分与改写(大表分页优化:延迟关联、书签分页)、join优化(小表驱动大表、 避免 cross join)、count的性能差异(count(1)、count(*)、count(字段))
4. 事务和锁机制
事务:ACID、四大隔离级别的定义及实现、默认个理解别为何是可重复读?隔离级别与并发问题(脏读、不可重复读、幻读)的对应关系
锁机制:锁的分类、行锁的触发条件、MVCC的原理、死锁的产生原因与定位、避免死锁的策略、高并发下如何减少锁竞争
5. 性能调优
MySQL核心配置参数的含义与调优依据、连接池配置、InnoDB 缓冲池、redo log 与 binlog 的协作、刷盘策略对性能与安全性的影响、磁盘IO优化、CPU与内存分配、网络优化
6. 高可用与集群架构
主从复制:复制原理、复制模式、复制延迟的原因与解决;
读写分离:读写分离的实现、一致性问题、分库分表的必要性与拆分策略;
高可用架构:主从切换工具、集群方案的适用场景、云原生
7. 数据安全与运维
备份与恢复:备份类型的选择、基于binlog的时间点恢复流程、大表备份的性能优化;
日志系统:binlog、redo log、慢查询日志与错误日志的分析;
故障付出:数据库宕机恢复流程、数据一致性校验、索引损坏的修复
8. 进阶特性与版本差异
MySQL 8.0新特性:窗口函数、CTE、角色管理与权限细化、innoDB的自增锁优化
特殊场景处理:大表DDL、JSON类型的存储与查询优化、地理信息(GIS)功能的实战应用
1. 基础核心
2. 索引
01. 各种树的原理和特性
学习树,是为了便于学习索引。索引的核心作用是“加速查询”,而高效的树结构正是实现这一点的关键。
答:
1. “树”形象的理解
可以从“现实中的树”类比数据结构的“树”,它和路边的树长得很像,只是“倒过来”了。
想象一棵简化的苹果树:
- 最底下的 “树根” 是起点,对应数据结构中树的根节点(只有一个);
- 从树根往上长的 “树干” 会分杈出 “树枝”,这些树枝就是父节点;
- 树枝再分杈出更细的枝桠,这些细枝桠就是子节点(一个父节点可以有多个子节点);
- 最顶端的 “苹果”(没有再分杈的部分),就是叶子节点。
数据结构里的 “树”,就是这样一种 “分层、有分支” 的结构: - 所有节点(根、父、子、叶子)都像 “果实” 一样,存储着数据(或索引);
- 节点之间的 “连接”(比如根到父、父到子)像 “树枝”,表示数据之间的关系;
- 整个结构是 “单向” 的:只能从根往下找子节点,不能从子节点反推回根(就像苹果不会自己长回树枝)。
举个更具体的例子:
- 如果用树存 “班级学生名单”,根节点可以是 “三年级”;
- 根节点的子节点(父节点)可以是 “三班”“五班”;
- “三班” 的子节点可以是 “男生组”“女生组”;
- “男生组” 的子节点(叶子节点)就是具体的学生:“小明”“小李”…
这种结构的核心好处是:查找效率高。
比如想找 “三年级三班男生组的小明”,你不用遍历所有学生,只需从根(三年级)→ 三班 → 男生组 → 小明,一步一步按 “分支” 找,比在一堆乱序的名单里翻快得多。
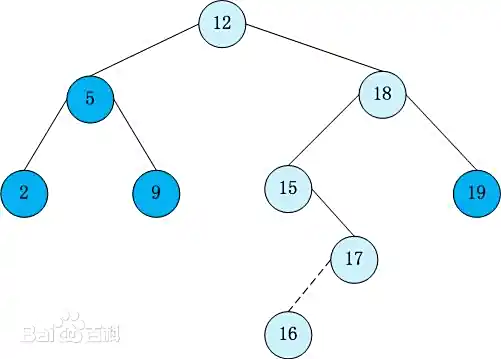
2. 二叉查找树
“不合适”的树(Binary Search Tree)
特性:每个节点最多 2 个子节点(左小右大),查询时从根节点开始,比当前节点小就走左子树,大就走右子树。
问题:容易 “失衡”。比如插入一串递增数据,会退化成链表(左子树为空,只有右子树),查询效率从 O (logn) 暴跌到 O (n)(和遍历链表一样慢)。
为什么 MySQL 不用:数据库索引需要稳定高效的查询,二叉树的失衡问题无法满足。
3. 平衡二叉树
又叫:AVL树/红黑树
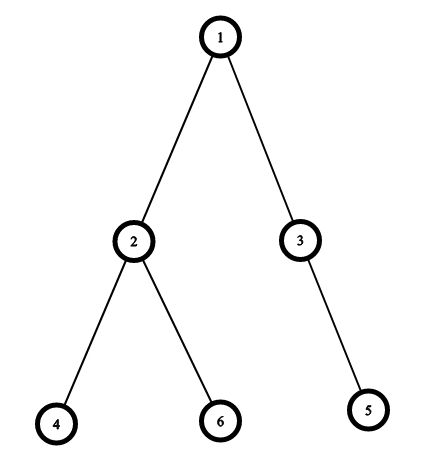
解决 “失衡”,但仍有局限
特性:在二叉查找树基础上,通过旋转保持 “平衡”(左右子树高度差不超过 1),确保查询效率稳定在 O (logn)。
问题:还是 “二叉”(每个节点最多 2 个子节点),导致树的 “高度过高”。
比如存 100 万条数据,平衡二叉树的高度大概是 20 层(2^20≈100 万)。
为什么 MySQL 不用:索引数据存在磁盘上,每次查询需要从磁盘读数据(一次 IO 读一个 “页”,比如 4KB)。树高 20 就意味着最多要读 20 次磁盘,IO 成本太高。
4. B 树
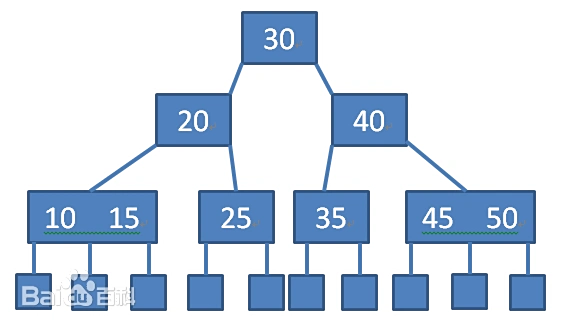
多路平衡查找树,降低高度
特性:
- “多路”:每个节点可以有多个子节点(比如 100 个),不再是二叉。
- “平衡”:所有叶子节点在同一层,避免某条路径过长。
- 节点存 “数据”:每个节点不仅存索引键,还直接存对应的数据(或数据地址)。
优势:高度大大降低。比如每个节点有 100 个子节点,存 100 万数据,树高只需 3 层(100^3=100 万),最多 3 次 IO 就能查到数据,比平衡二叉树高效得多。
为什么 MySQL 不完全用它:范围查询不方便。比如查 “id 从 100 到 1000”,B 树需要回溯父节点找下一个范围,效率低。
5. B + 树
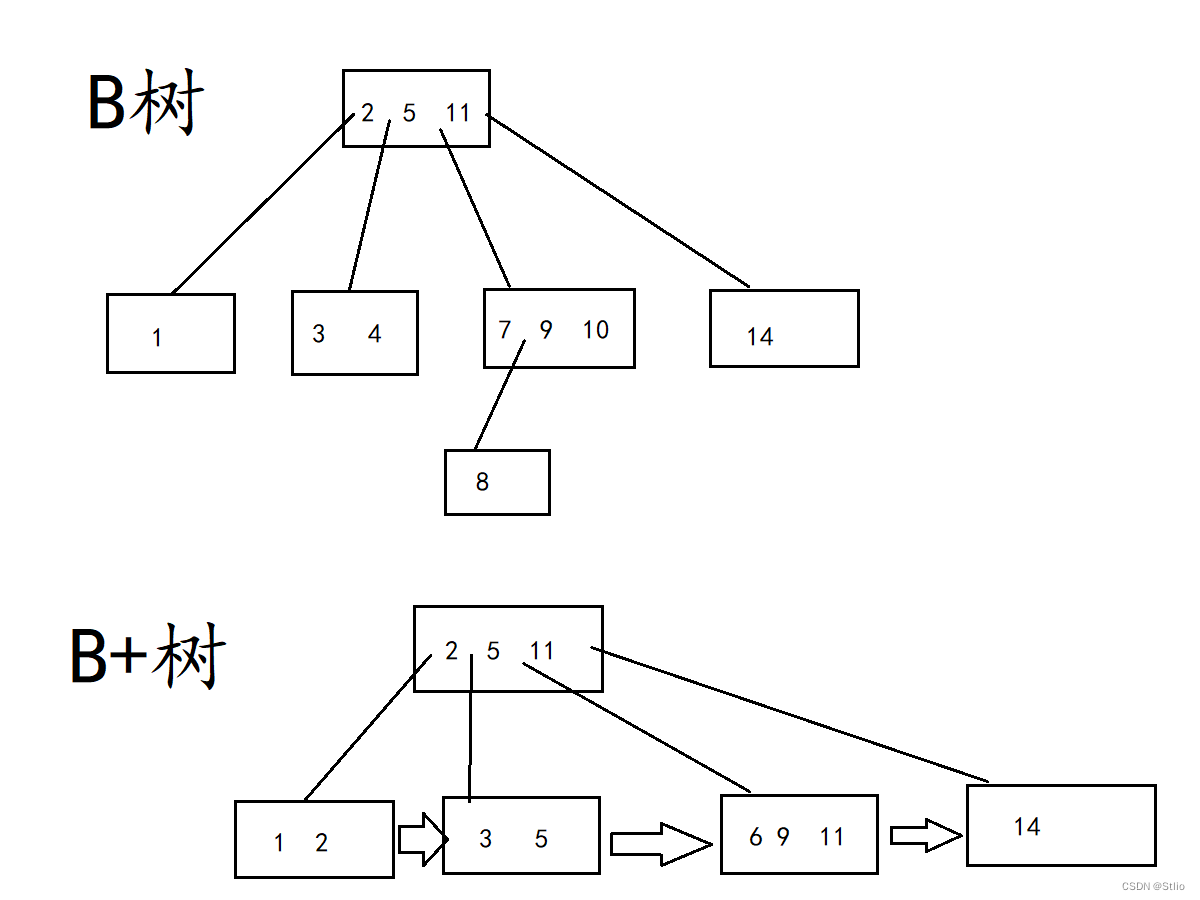
MySQL 索引的 “标准答案”
B + 树是 B 树的变种,专门为数据库索引优化设计,核心特性完美适配索引需求:
非叶子节点只存索引,不存数据:
- 非叶子节点仅保留索引键(比如 id),不存实际数据,这样一个节点能存更多索引键,子节点数量更多(比如 200 个),树高更低(100 万数据只需 2-3 层),IO 次数更少。
叶子节点存完整数据,且首尾相连:
- 所有实际数据只存在叶子节点,且叶子节点之间用链表连接(形成有序链表)。
对索引的核心价值:
- 单值查询快:和 B 树一样,通过索引键快速定位到叶子节点,IO 少。
- 范围查询无敌:比如查 “id>100”,找到第一个 id=100 的叶子节点后,直接顺着链表往后扫,不用回溯父节点,效率极高(MySQL 中范围查询很频繁,这是关键)。
6. MySQL 为什么选 B + 树做索引?
- 树高低,IO 次数少(磁盘读写效率高);
- 叶子节点有序相连,范围查询(如 between、in)效率远超其他树;
- 非叶子节点只存索引,节点存储密度高,进一步降低树高。
02. 索引的作用
答:
加速查询,降低IO:索引通过有序结构(如B+树)将分散的数据按索引键排序,查询时无需全表扫描,而是通过索引快速定位目标数据所在的磁盘位置,大幅减少磁盘IO次数(比如从扫描全表100万行降到扫描几十行);
保证数据唯一性,强化业务约束:通过唯一索引(含主键索引),数据库会强制约束索引键的值不重复,直接实现 “业务唯一标识” 需求(如用户 ID、订单号不可重复),避免手动校验的繁琐和风险。
优化排序与分组操作:索引本身是有序的,当查询包含
order by(排序)、group by(分组)时,可直接利用索引的有序性避免全表数据的额外排序(减少内存 / 磁盘临时表开销),提升这类操作的效率。
03. 常见索引类型及其特性
答:
1. 主键索引(Primary Key)
特性:
- 强制唯一性(表中唯一标识一行数据),且不允许NULL值;
- 一张表只能有一个主键索引;
- InnoDB 中主键索引是聚簇索引(叶子节点直接存储整行数据),无需回表,查询效率最高。
适用场景:作为表的唯一标识(如用户 ID、订单 ID),确保数据唯一性并加速行查询。
2. 唯一索引(Unique Index)
特性:
- 确保索引列的值唯一,但允许NULL值(且NULL可出现多次);
- 一张表可创建多个唯一索引;
- 基于 B + 树结构,非聚簇索引(叶子节点存主键值,需回表查数据);
- 查询时找到一个匹配值就停止扫描(无需确认是否有重复),比普通索引少了 “继续校验” 的步骤,回表前的索引定位效率更高。
适用场景:需唯一约束但非主键的字段(如手机号、邮箱,允许未填写即NULL)。
3. 普通索引(Normal Index)
特性:
- 最基础的索引类型,无唯一性约束,允许重复值和NULL;
- 基于 B + 树结构,非聚簇索引,仅用于加速查询,不影响数据本身的约束;
- 查询时需扫描所有匹配的索引节点(可能有多个重复值),再批量回表取数据,比唯一索引多了 “扫描重复索引” 的开销。
适用场景:高频查询的非唯一字段(如商品分类、用户昵称),单纯提升查询效率。
4. 联合索引(Composite Index)
特性:
- 由多个字段组合创建(如(a, b, c)),遵循最左前缀原则(查询需包含最左字段才能命中索引);
- 索引按第一个字段排序,第一个字段相同则按第二个,以此类推;
- 可覆盖多字段查询,减少回表(如查询a, b时,若联合索引包含a, b,则无需回表);
- 效率依赖查询条件:仅命中最左前缀且为覆盖索引时(无需回表),效率接近普通索引;若未命中全部前缀或需回表,效率会下降。
- 整体比普通索引慢的核心:索引结构是多字段排序,定位时需匹配多个字段的有序性,逻辑比单字段索引复杂。
适用场景:多字段组合查询(如 “按用户 ID + 订单状态查询”),需合理设计字段顺序(区分度高的字段放左侧)。
5. 前缀索引(Prefix Index)
特性:
- 仅对字符串字段的前 N 个字符创建索引(如index(name(10))),大幅节省存储空间,但索引选择性低(重复率高);
- 适用于长字符串(如 URL、长文本),但可能降低索引选择性(重复率升高),且无法用于order by/group by或覆盖索引。
- 查询时需扫描更多索引节点才能定位目标,且无法使用覆盖索引(必须回表),额外增加 IO 开销。
适用场景:长字符串字段的模糊查询(如like ‘abc%’),平衡空间与查询效率。
6. 全文索引(Full-Text Index)
特性:
- 针对大文本内容(如文章、评论)的关键词搜索,针对大文本分词匹配(而非like的字符匹配,非 B + 树精确查找,需先分词、匹配倒排索引,再关联原表数据);
- 效率远高于like ‘%关键词%’,但仅支持MATCH() AGAINST()语法,且有最小 / 最大词长限制。
- 逻辑复杂度远高于其他索引,仅适合关键词检索,单值精确查询效率远低于 B + 树结构的索引。
适用场景:全文检索需求(如博客系统的文章关键词搜索)。
这些索引类型,按照查询速度和效率,从高到低排序
基于InnoDB引擎、但是精确查询场景:
查询效率从高到低排序:主键索引 > 唯一索引 > 普通索引 > 联合索引(命中最左前缀 + 覆盖索引)> 前缀索引 > 全文索引
但是并非绝对,依旧需要结合使用场景进行判断。
排序前提:默认是「单值精确查询」,若为「范围查询」,主键索引和唯一索引的差距会缩小(范围查询需扫描多个节点)。
04. 聚簇索引与非聚簇索引的区别
答:
聚簇索引与非聚簇索引的核心区别是:数据存储位置。
聚簇索引的叶子节点存储整行数据;非聚簇索引的叶子节点仅存储 “索引键 + 主键值”,需通过主键回表查询完整数据(覆盖索引除外)。

05. 联合索引的最左前缀原则
答:
最左前缀原则:
查询条件必须从联合索引的最左字段开始匹配,且连续匹配,才能用到索引的对应部分。
举个例子:联合索引(name, age, score)
能命中索引的情况(从左到右连续匹配):
where name = '张三'(只用name,命中索引的name部分);where name = '张三' and age = 20(用name+age,命中索引的name+age部分);where name = '张三' and age = 20 and score > 90(用name+age+score,命中索引的全部三部分)。
不能命中索引的情况(跳过左字段或不连续):
where age = 20(跳过最左的name,完全无法命中);where name = '张三' and score > 90(跳过中间的age,只能命中name部分,score无法利用索引)。
联合索引含范围查询或模糊查询能否命中索引?
对于范围查询(大于、小于等)会导致“当前字段右侧的索引字段失效”,但左侧已匹配的字段仍能命中,(当前字段也能命中);
对于模糊查询,如果是前缀模糊(例如:"快乐大本营",like '快乐%'),能命中当前字段及左侧的索引,但当前字段右侧的索引失效;如果是后缀/全模糊查询(例如:%大本营、%乐大%),会导致当前字段及右侧字段的索引都失效,仅当前字段左侧已匹配索引有效。
06. 索引的维护成本
答:
MySQL索引的维护成本本质是“空间换时间”的代价,主要集中在“写入性能损耗”、“存储空间占用”、“索引碎片维护”。索引数量越多,结构越复杂,则维护成本越高。
1. 写入操作(插入/更新/删除)的性能损耗
- 写入数据时,不仅要修改表数据,还需同步维护索引的 B + 树结构。
- 插入:可能触发 B + 树节点分裂(如节点满时),需重新组织索引排序;若为唯一索引,还需额外校验唯一性(扫描索引确认无重复)。
- 更新:若更新的是索引列,需先删除旧索引条目,再插入新索引条目,相当于两次索引操作;非索引列更新不影响索引,但仍需维护聚簇索引的物理顺序(InnoDB)。
- 删除:不会立即释放索引空间,仅标记为 “删除”,后续需通过碎片整理回收,且可能触发 B + 树节点合并(如节点数据过少时)。
2. 存储空间的额外占用
- 索引需独立存储 B + 树结构,一张表的索引越多、字段越长,占用的磁盘空间越大。
- 示例:大表的联合索引、长字符串的前缀索引,可能占用与数据本身相当的存储空间;聚簇索引虽无需额外存数据,但非聚簇索引(如唯一、普通索引)需存储主键值,叠加后空间开销显著。
3. 索引碎片与定期维护开销
- 频繁插入 / 删除后,B + 树会产生 “空洞”(已删除但未释放的空间),导致索引碎片增多。
- 碎片会降低查询效率(磁盘 IO 增多),需定期执行维护操作(如
OPTIMIZE TABLE、重建索引),这些操作会锁表或占用大量 IO 资源,影响业务高峰期性能。
4. 优化器的决策负担
- 表中索引过多时,MySQL 优化器需遍历所有可能的索引组合,评估最优查询计划,导致查询解析时间变长(尤其复杂查询场景)。
如何优化维护策略
- 不同索引的维护成本差异:联合索引 > 普通索引 > 唯一索引 > 主键索引(结构越复杂,维护时 B + 树调整逻辑越繁琐);前缀索引、全文索引的维护成本高于单字段索引(前者需处理部分字符,后者需维护分词倒排索引)。
- 平衡维护成本的核心原则:避免 “过度索引”,仅为高频查询字段创建索引;优先选择窄索引(短字段、少字段组合),减少存储空间和维护开销;定期监控索引使用率,删除无效索引(如长期未被使用的索引)。
07. MySQL回表查询与索引覆盖
答:
回表查询是 “非聚簇索引查询后需二次查聚簇索引拿完整数据” 的过程;
索引覆盖是 “查询字段(即所需的返回字段)全在索引中,无需二次查询” 的优化场景。
二者是 “需回表” 与 “免回表” 的对立关系,直接影响查询效率。
1. 回表查询(Bookmark Lookup)
1. 定义
当使用非聚簇索引(如唯一索引、普通索引、联合索引)查询时,若查询字段未完全包含在该索引中,需先通过非聚簇索引找到 “索引键 + 主键值”,再用主键值查询聚簇索引(主键索引) ,才能获取整行完整数据,这个 “二次查询” 的过程就是回表。
2. 核心逻辑(结合 InnoDB 引擎)
- 非聚簇索引的叶子节点仅存储 “索引键 + 主键值”,不存完整行数据。
- 若查询需要非索引字段(如用唯一索引
email查user表的主键id和非索引字段name),必须通过主键值回聚簇索引 “兜底”,才能拿到name。
3. 示例
-- 表结构:id(主键)、email(唯一索引)、name(非索引字段)
select id, name from user where email = 'a@test.com';第一步:通过唯一索引email(非聚簇)找到主键id=100;
第二步:用id=100查询聚簇索引,拿到name字段,完成查询;
这两步共同构成回表查询,额外增加了一次聚簇索引查询的 IO 开销。
2. 索引覆盖(Covering Index)
1. 定义
当查询的所有字段(包括筛选条件、返回字段)都包含在某一个索引中时,则无需回表,仅通过该索引就能获取所有需要的数据,这个索引就是 “覆盖索引”,对应的查询就是覆盖索引查询。
2. 核心优势
避免回表,减少一次磁盘 IO(聚簇索引查询),大幅提升效率;
索引数据量远小于全表数据,查询时扫描的数据量更少。
3. 示例
-- 联合索引:idx_email_name(email, name)(包含email和name字段)
select email, name from user where email = 'a@test.com';查询的筛选字段email、返回字段name均在联合索引中;
直接通过该联合索引就能拿到所有需要的数据(返回字段),无需回聚簇索引,实现 “一次查询完成”。
3. 补充项
触发条件对比:
- 回表:非聚簇索引 + 查询字段超出索引范围;
- 索引覆盖:查询字段(筛选 + 返回)完全匹配某一索引(单字段索引或联合索引)。
实战价值:
索引覆盖是优化回表开销的核心手段,设计索引时可将高频查询字段加入联合索引(如idx_userid_status(user_id, status)),避免回表;
聚簇索引查询天然支持 “索引覆盖”(叶子节点存完整数据),无需回表,这也是其查询效率最高的原因之一。
易混点:
索引覆盖的关键是 “字段全包含”,与索引类型无关(单字段索引、联合索引均可作为覆盖索引);
前缀索引无法实现索引覆盖(仅存字段前 N 个字符,无法返回完整字段值)。
4. 不能触发索引覆盖示例
SELECT id, name, email FROM user WHERE email = 'xxx@qq.com';
-- 在user表中,id是主键,email是唯一索引,name是普通索引结论:不能触发索引覆盖。
索引覆盖的核心要求是查询的所有字段(筛选条件 + 返回字段)必须完全包含在同一个索引中,跨索引无法实现覆盖。
如何修改才能触发索引覆盖?
- 创建联合唯一索引
unique index idx_email_name(email, name) - 筛选字段
email、返回字段email、name、id(主键会自动包含在非聚簇索引中),全部包含在这个联合索引里; - 查询时无需回表,直接通过该联合索引就能获取所有需要的数据,触发索引覆盖。
08. 如何合理使用索引?
以业务查询为导向,平衡查询效率与维护成本,避免 “过度索引” 或 “无效索引”。
- 优先为 “高频查询字段” 建索引,低频查询不建;
- 联合索引需遵循 “最左前缀 + 区分度优先(区分度高,重复值少)” 原则;
- 避免索引失效场景,确保索引被正确使用;
- 利用 “索引覆盖” 减少回表,提升效率;
- 根据字段特性选择合适的索引类型;
- 定期维护索引,清理无效索引。
合理使用索引的核心是 “按需设计、避免失效、注重维护”。
“索引不是越多越好,而是越合适越好”。
09. 索引失效场景
MySQL 索引失效的本质是:查询条件破坏了索引的有序性或匹配规则;
常见场景集中在:“字段操作”、“类型不匹配”、“查询语法不当”三类;
避免核心是:让查询条件贴合索引设计规则。
以下是常见索引失效场景 + 避免方法:
1. 对索引字段做函数 / 运算操作
失效场景:查询时对索引字段用函数(如substr、date_format)或数学运算,会导致 MySQL 无法利用索引的有序性,只能全表扫描。
- 示例:
where substr(name, 1, 3) = '张三'(name是普通索引)、where age + 1 = 20(age是普通索引)。
避免方法:将函数 / 运算移到等号右侧,或提前计算结果。
- 优化后:
where name like '张三%'、where age = 19。
2. 隐式类型转换
失效场景:查询条件中字段类型与传入值类型不匹配,MySQL 会自动做类型转换,导致索引失效。
- 示例:
where phone = '13800138000'(phone是int类型,字符串转数字)、where id = '100'(id是int,字符串转数字)。
避免方法:确保查询值类型与字段类型完全一致。 - 优化后:
where phone = 13800138000、where id = 100。
3. 模糊查询(非前缀匹配)
失效场景:like的模糊查询若以%开头(后缀模糊 / 全模糊),会破坏索引有序性,导致索引失效;前缀模糊(%在末尾)可正常使用索引。
- 示例:
where name like '%张三'(后缀模糊,失效)、where name like '%张三%'(全模糊,失效)。
避免方法:优先用前缀模糊查询;若需全模糊,改用全文索引(如fulltext index)或应用层分词。 - 优化后:
where name like '张三%'(前缀模糊)、MATCH(name) AGAINST('张三')(全文索引)。
4. 联合索引不满足最左前缀原则
失效场景:联合索引(如(a, b, c))需从左到右连续匹配,跳过左侧字段或不连续匹配,会导致索引失效或部分失效。
- 示例:
where b = 2 and c = 3(跳过最左a,全失效)、where a = 1 and c = 3(跳过中间b,仅a部分生效,c失效)。
避免方法:查询条件需包含联合索引的最左字段,且按索引字段顺序匹配;若高频查询b + c,可单独建联合索引(b, c)。 - 优化后:
where a = 1 and b = 2 and c = 3(全生效)、where b = 2 and c = 3(改用(b, c)联合索引)。
5. 范围查询后字段失效
失效场景:联合索引中,某字段用>、<、>=、<=、between做范围查询后,其右侧的索引字段会失效。
- 示例:
where a = 1 and b > 2 and c = 3(联合索引(a, b, c),c失效)。
避免方法:将范围查询字段放在联合索引的最右侧;若需多字段范围查询,改用覆盖索引或拆分查询。 - 优化后:
where a = 1 and b > 2(仅用a + b索引)、建联合索引(a, b, c)并确保查询字段覆盖(select a, b, c,避免回表)。
6. or连接非索引字段
失效场景:or连接的查询条件中,若有一个字段无索引,会导致整个查询无法使用索引(MySQL 会选择全表扫描)。
- 示例:
where name = '张三' or address = '北京'(name有索引,address无索引,全失效)。
避免方法:确保or连接的所有字段都有索引;或改用union all拆分查询(需字段一致)。 - 优化后:
where name = '张三' union all where address = '北京'(address补建索引)。
7. is not null/not in/not exists
失效场景:对索引字段用is not null(部分场景失效)、not in、not exists,会破坏索引的匹配逻辑,导致失效(is null通常可使用索引)。
- 示例:
where name is not null(name是普通索引,可能失效)、where id not in (1,2,3)(id是主键索引,大数据量下失效)。
避免方法:is not null改用union拼接非空结果;not in改用left join ... on ... is null;小数据量not in可接受,大数据量必优化。 - 优化后:
where id in (select id from user) union ...(is not null替代)、select * from user u left join tmp t on u.id = t.id where t.id is null(not in替代)。
8. 索引选择性差(失效等价场景)
失效场景:索引字段重复率极高(如 “性别” 字段,仅男 / 女),MySQL 优化器会判断 “全表扫描比索引查询更快”,主动放弃使用索引。
- 示例:
where gender = '男'(gender建了索引,但全表 80% 是男性,索引失效)。
避免方法:不针对低选择性字段建单字段索引;若需查询,将其作为联合索引的右侧字段(如(age, gender)),通过高选择性字段先过滤。
9. 补充
- 验证索引是否失效的核心方法:用
explain分析执行计划,若key字段为NULL或非目标索引,说明索引失效。 - 特殊情况:
Innodb的聚簇索引(主键)即使有上述场景(如is not null),通常也不会完全失效,因聚簇索引的物理存储特性,优化器更倾向使用。 - 避免失效的核心原则:不破坏索引的有序性、不改变字段的原始形态、让查询条件贴合索引设计。
10. explain执行计划分析
explain 是 MySQL 分析 SQL 执行计划的核心工具。
通过输出 12 个字段(面试重点关注 7 个核心字段),可判断索引是否生效、查询是否全表扫描、是否存在文件排序 / 临时表等性能问题。
1. explain 核心作用
- 判断 SQL 是否使用了目标索引(避免索引失效);
- 识别全表扫描、文件排序、临时表等低效操作;
- 分析表的连接顺序、查询类型(简单 / 复杂查询);
- 预估查询扫描的行数,评估查询效率。
2. 7 个核心字段解析
1. type:访问类型
核心,判断查询效率的关键
含义:表示 MySQL 如何访问表中的数据(即查询方式),取值决定查询效率,从优到差排序:
system > const > eq_ref > ref > range > index > ALL
关键取值解读:
system:表中只有 1 行数据(如系统表),效率最高(罕见);
const:通过主键 / 唯一索引查询,匹配 1 行数据(如where id=100),高效;
eq_ref:多表连接时,被连接表通过主键 / 唯一索引匹配,每行只返回 1 行(如join on 主键);
ref:通过普通索引 / 联合索引前缀匹配,返回多行匹配数据(如where name=’张三’,name 是普通索引);
range:范围查询(>、<、between、in),只扫描索引的某一范围(比ref差,但比全表扫描好);
index:扫描整个索引树(索引全扫描),比ALL好(索引数据量小于全表);
ALL:全表扫描(最差),需避免(通常是索引失效或未建索引)。
判断标准:type至少要达到range级别,最优是ref或const,出现ALL说明存在性能问题。
2. key:实际使用的索引
含义:表示 MySQL 实际选择的索引(若为NULL,说明未使用任何索引,索引失效或无合适索引);
判断标准:若key不是你设计的目标索引(如预期用idx_email,但key为NULL),说明索引失效,需排查原因(结合索引失效场景)。
3. rows:预估扫描行数
含义:MySQL 优化器预估的、查询需要扫描的行数(非精确值,但可反映效率);
判断标准:行数越少越好,若rows远大于表中实际数据量,可能是统计信息过时(需执行analyze table更新),或索引设计不合理。
4. extra:额外执行信息
核心!暴露性能隐患
含义:记录 SQL 执行的额外操作,重点关注 “好的标识” 和 “坏的标识”:
- 优质标识:
Using index:触发覆盖索引,无需回表(高效,面试加分点);Using index condition:索引下推(ICP),减少回表次数(高效)。
- 性能隐患标识(必须避免):
Using filesort:需在内存 / 磁盘中排序(未利用索引有序性,如order by字段无索引);Using temporary:创建临时表存储中间结果(如group by无索引、多表连接无合适索引,性能极差);Using where:全表扫描后过滤数据(type=ALL时出现,说明无索引可用);Using join buffer:多表连接时未用索引,使用连接缓冲区(低效)。
5. id:查询执行顺序
含义:表示查询中每个select子句的执行顺序(数字越大越先执行,相同数字按从上到下顺序);
应用场景:复杂查询(子查询、join)中,判断表的连接顺序是否合理(如小表驱动大表)。
6. select_type:查询类型
含义:区分简单查询和复杂查询,面试高频取值:
SIMPLE:简单查询(无子查询、无union);SUBQUERY:子查询(select中嵌套select);DERIVED:派生表(from中嵌套select);UNION:union连接的第二个及以后的查询。
面试价值:说明查询的复杂程度,复杂查询(如多层子查询)可能导致优化器选择低效执行计划,需考虑拆分 SQL。
7. table:当前查询的表
含义:显示 SQL 查询的表名(或别名),多表连接时按id顺序显示表的执行顺序。
加项
如何判断索引是否生效:
看key字段是否为目标索引(非NULL),同时type不是ALL/index;如何判断查询是否高效:
type≥range+key非NULL+rows值小 +extra无filesort/temporary;常见问题排查:
- 若
type=ALL+key=NULL:索引失效或未建索引,排查索引失效场景; - 若
extra有filesort:order by/group by字段未建索引,需添加索引; - 若
extra有temporary:group by无索引或多表连接无合适索引,优化索引设计。
- 若
explain extended:在explain基础上增加filtered字段(过滤行数占比),filtered越高说明过滤效果越好;explain format=json:输出 JSON 格式的详细执行计划,适合复杂查询分析;执行计划是 “预估” 而非 “实际”:优化器可能因统计信息过时、索引选择性差等误判,需结合实际执行耗时验证。

很多名词,我也没那么了解,😂
我也是,用会用,但是没有系统的学习整理过,很多东西早都忘了,所以现在系统性整理一遍。