基础核心
回目录: 《面试笔记:MySQL 相关目录》
下一篇: 《面试笔记:MySQL 相关02 – 索引》
01. 整体架构
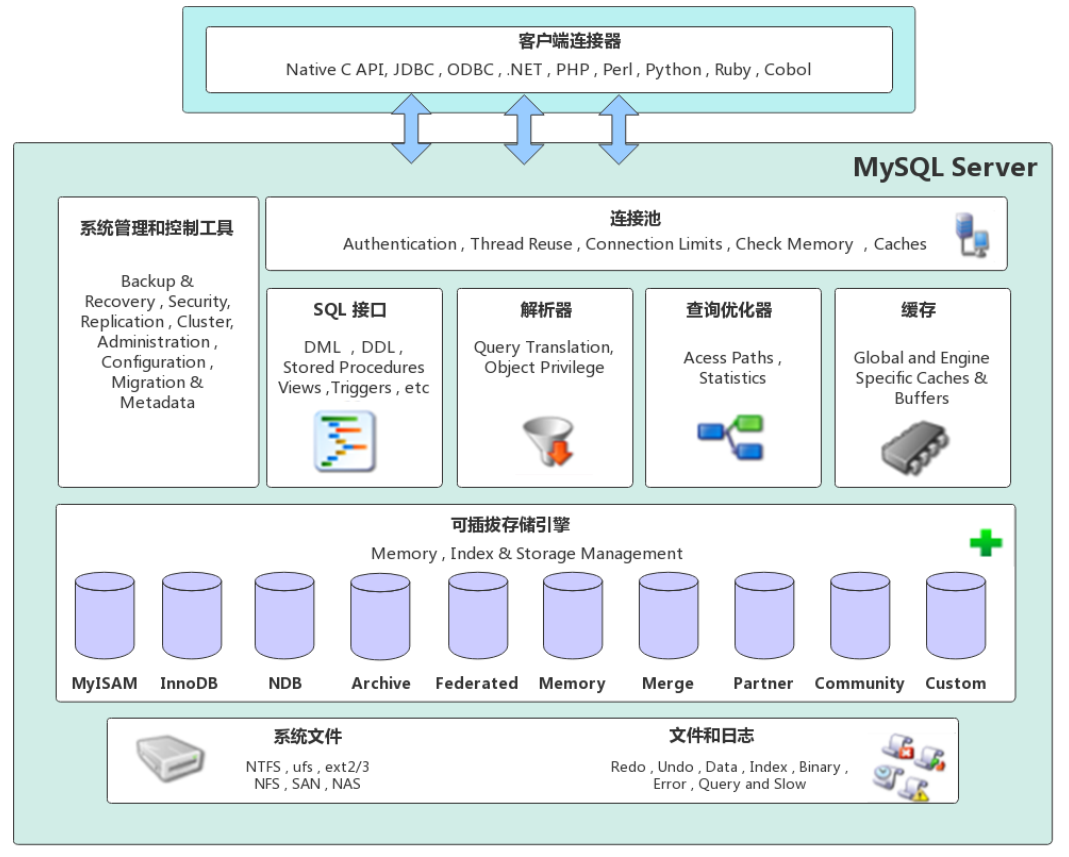
以5.7版本为基础,8.0的更改会特别标注。
MySQL 采用分层架构,整体可分为 4 层。
连接层、服务层、存储引擎层、文件系统层。
1. 连接层
客户端连接层
- 负责接收客户端(如Java程序、Navicat等)的TCP/IP连接请求,处理身份认证(用户名、密码、主机权限校验)。
- 提供连接池机制,复用已建立的连接(避免频繁 TCP 握手 / 挥手的开销),同时管理连接状态(如空闲超时断开)。
- 核心组件:连接器(验证用户名密码、权限)、连接池(复用已建立的连接,减少握手开销)。
- 8.0版本变化:
- 认证插件升级:默认使用
caching_sha2_password替代 5.7 的mysql_native_password,加密强度更高,需客户端(如 JDBC 驱动)适配支持。 - 连接池优化:增强连接复用效率,减少空闲连接占用的资源,同时支持 “连接属性动态修改”(无需重启连接即可调整部分参数)。
- 认证插件升级:默认使用
2. 服务层
核心处理层
- 所有存储引擎共享的核心层,负责 SQL 的 “解析 – 优化 – 执行” 全流程,不直接操作数据,仅通过接口调用存储引擎。
- 包含查询缓存(默认关闭)、解析器、优化器、执行器等核心逻辑。
- 统一处理日志(如 binlog)、权限二次校验(执行 SQL 前再次确认权限)等通用逻辑。
- 核心流程:接收 SQL 后,先查查询缓存(若命中直接返回)→ 解析器生成语法树(检查 SQL 语法)→ 优化器生成最优执行计划(如选择索引、连接方式)→ 执行器调用存储引擎接口执行计划。
- 8.0版本变化:
- 移除查询缓存组件:因 5.7 中查询缓存命中率极低(数据更新会清空对应表缓存),8.0 直接删除该模块,简化服务层逻辑,避免无效开销。
- 优化器增强:架构层面支持更多优化规则(如复杂 JOIN 的执行计划调整)。
- binlog 默认开启:5.7 中 binlog 默认关闭,8.0 默认启用,且架构上支持 binlog 的 “即时回放”(加速主从同步),无需额外配置。
3. 存储引擎层
数据存储层
- 采用 “插件式架构”,可动态加载不同存储引擎(如 InnoDB、MyISAM),负责数据的实际存储、读取和事务管理。
- 与服务层通过统一的
handler接口交互,服务层无需关心底层数据存储格式(如 InnoDB 的表空间、MyISAM 的文件存储)。 - 默认存储引擎为 InnoDB,架构上支持事务、行锁等特性的底层实现。
- 8.0版本变化:
- 强化 InnoDB 的架构适配:移除其他低效存储引擎(如 Federated),仅保留 InnoDB、MyISAM、Memory 等常用引擎,聚焦 InnoDB 的性能优化。
- 架构层面支持 InnoDB 的新特性:如自增 ID 持久化(通过 redo log 架构实现)、隐藏索引(架构上支持索引的 “逻辑禁用”,不影响物理存储)。
- 锁机制架构优化:行锁的范围判断逻辑在架构层面更精准,减少锁冲突(依赖与服务层的接口交互优化)。
4. 文件系统层
- 负责将数据、日志等持久化到磁盘,依赖操作系统的文件系统(如 ext4、NTFS)。
- 存储文件类型包括:表空间文件(InnoDB 的
.ibd)、日志文件(redo log(重做日志)、binlog(二进制日志)、undo log(回滚日志))、配置文件(my.cnf)等。 - 8.0版本变化:
- 日志文件架构调整:redo log 默认存储路径优化,支持更大的日志文件大小(默认单个文件 1GB,5.7 默认 48MB),提升崩溃恢复效率。
- 表空间文件优化:默认使用独立表空间(5.7 需手动配置),且架构上支持 “表空间加密”(透明数据加密 TDE),文件存储更安全。
- 自增 ID 存储架构变更:5.7 中自增 ID 存于内存,8.0 架构上改为写入 redo log,重启后可通过日志恢复自增 ID 序列,避免重复。
02. 核心组件
1. 连接器
Connection Manager
核心功能:负责客户端连接的建立、管理与身份认证,是客户端与 MySQL 交互的 “入口”。
- 接收 TCP 连接请求后,校验用户名、密码及客户端主机权限(基于mysql.user表),通过后分配连接线程。
- 维护连接状态(如空闲、活跃),默认空闲超时时间为 8 小时(wait_timeout参数控制),超时后自动断开。
- 认证依赖
mysql_native_password插件(默认),加密强度一般,兼容性好。 - 8.0 版本变化:
- 默认认证插件升级为
caching_sha2_password,采用 SHA-256 加密,安全性更高(需客户端驱动支持,如 JDBC 需 8.0 + 版本)。 - 优化连接复用机制,减少空闲连接的资源占用,支持 “连接属性动态修改”(如无需重连即可调整部分会话参数)。
- 默认认证插件升级为
2. 查询缓存
Query Cache
核心功能:缓存 SQL 语句与结果集,相同 SQL(字节级一致)可直接返回缓存结果,减少重复计算。
- 存在但默认关闭(
query_cache_type=OFF),需手动开启;缓存以表为单位,表数据更新(增删改)时会清空该表所有缓存。 - 局限性明显:仅适用于静态数据(如配置表),高并发写场景下命中率极低,反而因缓存维护消耗资源。
- 8.0 版本变化:
- 彻底移除查询缓存组件(相关参数如
query_cache_size失效),原因是其实际应用价值低,移除后简化了服务层逻辑,减少无效开销。
- 彻底移除查询缓存组件(相关参数如
3. 解析器
Parser
核心功能:对 SQL 语句进行语法分析,生成 “语法树”,确保 SQL 符合语法规则。
- 解析过程包括:词法分析(识别关键字、表名、字段名等)→ 语法分析(检查 SQL 结构是否合法,如
SELECT后是否有字段、WHERE是否搭配条件)。 - 若语法错误(如关键字拼写错误),直接返回报错(如 “you have an error in your SQL syntax”)。
- 8.0 版本变化:
- 核心功能不变,但扩展了对新语法的支持(如
WITH RECURSIVE递归查询、降序索引语法),解析效率略有优化(减少语法树生成的内存占用)。
- 核心功能不变,但扩展了对新语法的支持(如
4. 优化器
Optimizer
核心功能:基于语法树生成 “最优执行计划”,目标是最小化执行成本(CPU、IO 开销)。
- 优化逻辑包括:选择合适的索引(如判断全表扫描 vs 索引扫描更快)、调整多表连接顺序(小表驱动大表减少中间结果集)、简化表达式(如
a=1 and a=2直接判定为无效)。 - 依赖表统计信息(如行数、数据分布),但统计信息更新不及时可能导致执行计划偏差。
- 8.0 版本变化:
- 增强统计信息:引入 “直方图”(Histogram),更精准记录数据分布(如字段值的频率),优化器对非均匀分布数据的索引选择更合理。
- 优化规则扩展:支持复杂 JOIN(如多表嵌套连接)的执行计划调整,子查询优化更彻底(减少 “派生表” 的临时表开销)。
5. 执行器
Executor
核心功能:根据优化器生成的执行计划,调用存储引擎接口执行操作,并返回结果。
- 执行前再次校验权限(避免连接建立后权限被修改导致的安全问题)。
- 例如:检查用户是否有目标表的
SELECT权限。
- 例如:检查用户是否有目标表的
- 通过统一接口(如
handler::read_row)调用存储引擎,获取数据后进行过滤、聚合等处理(如WHERE条件过滤、GROUP BY分组)。 - 8.0 版本变化:
- 优化接口调用效率,减少与存储引擎的交互次数(如批量读取数据)。
- 支持 “即时执行”(Instant Execution),对简单查询可跳过部分优化步骤,直接执行,提升响应速度。
6. 日志组件
核心日志模块
负责记录 MySQL 的操作和状态,支撑数据恢复、主从同步等功能。
1. binlog(二进制日志)
- 5.7 版本:默认关闭,需手动开启(
log_bin=ON)。记录所有数据修改操作(增删改、DDL),格式支持STATEMENT(语句)、ROW(行)、MIXED(混合),用于主从同步和时间点恢复。 - 8.0 版本:默认开启。格式默认
ROW(更安全),支持 “即时回放”(Binlog Instant),主从同步时可跳过部分无效日志,提升同步效率。
2. redo log(重做日志,InnoDB 依赖)
- 5.7 版本:InnoDB 专属,记录数据页的物理修改,采用 “循环写” 机制(固定大小文件),保证崩溃后数据可恢复(先写日志再写磁盘,即 WAL 机制)。
- 8.0 版本:默认单个日志文件大小从 48MB 增至 1GB,减少日志切换频率;支持 “并行写入”,提升高并发下的日志写入效率。
3. undo log(回滚日志,InnoDB 依赖)
- 5.7 版本:记录数据修改前的状态,用于事务回滚和 MVCC(多版本并发控制),默认随表空间存储,可能因长期积累导致空间膨胀。
- 8.0 版本:支持 “undo log 自动回收”(通过
innodb_undo_log_truncate参数),无需手动清理,减少维护成本。
7. 权限组件
核心功能:管理用户权限,控制对数据库、表、字段的操作权限。
- 权限存储在
mysql库的系统表中(如user、db、tables_priv),权限修改后需通过FLUSH PRIVILEGES刷新或重启生效(静态权限)。 - 支持库级、表级、列级权限,但缺乏细粒度的动态权限(如管理特定日志的权限)。
- 8.0 版本变化:
- 引入 “动态权限”(如
BINLOG_ADMIN、BACKUP_ADMIN),权限修改后即时生效,无需刷新或重启。 - 权限检查逻辑优化,结合角色(Role)管理(5.7 后期引入但不完善,8.0 强化),可批量分配权限,简化权限管理。
- 引入 “动态权限”(如
8. 总结
MySQL 核心组件的核心逻辑(连接、解析、优化、执行、日志、权限)在 5.7 和 8.0 中保持一致。
8.0 的改进集中在:移除低效组件(查询缓存)、增强安全性(认证插件)、优化性能(优化器、日志)、简化维护(动态权限、undo 回收)等。
03. 存储引擎
MySQL 的存储引擎是负责数据存储、读取及底层特性实现的核心模块,采用 “插件式” 设计,不同引擎支持的功能(如事务、锁机制)差异显著。
1. InnoDB(默认)
InnoDB 是 MySQL 最常用(默认)的存储引擎,以事务支持、高并发为核心优势,5.7 和 8.0 均将其作为默认引擎,版本间优化集中在性能、可靠性和功能扩展。
核心通用特性(5.7 和 8.0 共通)
- 支持事务(ACID 特性):通过 redo log(保证持久性)、undo log(保证原子性和隔离性)实现。
- 行级锁:仅锁定修改的行(而非全表),适合高并发写场景(如电商订单更新)。
- 聚簇索引:数据与主键索引物理存储在一起,查询主键时效率极高。
- 外键约束:支持表间外键关联(如orders表关联users表的user_id)。
5.7 版本 InnoDB 特性
- 自增 ID(AUTO_INCREMENT):存储在内存中,重启 MySQL 后可能因未持久化导致重复(需依赖 binlog 恢复,但存在风险)。
- 索引限制:仅语法支持降序索引(DESC),实际仍按升序存储,查询降序数据时需额外排序。
- 锁机制:间隙锁(Gap Lock)范围较宽泛,可能导致高并发下锁冲突增加(如批量插入相邻 ID 时)。
- undo log:默认随表空间存储,长期运行后可能因未自动回收导致磁盘空间膨胀(需手动清理)。
8.0 版本 InnoDB 关键改进
- 自增 ID 持久化:将自增 ID 写入 redo log,重启后可通过日志恢复,彻底解决 5.7 的重复问题。
- 索引增强:
- 真正支持降序索引(DESC),查询降序排序数据时无需额外排序,直接使用索引。
- 新增 “隐藏索引”(INVISIBLE):可标记索引为隐藏(不影响物理存储),用于临时禁用索引测试性能(无需删除重建)。
- 锁优化:间隙锁范围更精准,减少非必要锁定(如批量插入时仅锁定实际需要的区间),降低锁冲突。
- undo log 自动回收:支持innodb_undo_log_truncate参数(默认开启),自动收缩过大的 undo log,减少人工维护成本。
- 表空间加密:支持透明数据加密(TDE),表空间文件(.ibd)加密存储,提升数据安全性。
2. MyISAM
MyISAM 是早期 MySQL 的默认引擎,因不支持事务和行锁,逐渐被 InnoDB 替代,5.7 和 8.0 中仍保留但应用场景有限。
核心通用特性(5.7 和 8.0 共通)
- 不支持事务和外键:仅适合无需事务保证的场景。
- 表级锁:写操作(增删改)会锁定全表,读操作需等待写锁释放,并发写性能差。
- 独立文件存储:数据存于.MYD文件,索引存于.MYI文件,可直接复制文件迁移表。
5.7 版本:仍有部分场景使用(如只读日志表),但已明确不推荐用于核心业务。
8.0 版本:进一步弱化 MyISAM,默认配置下性能优化倾向 InnoDB,且移除了部分对 MyISAM 的冗余支持(如全文索引的部分优化仅针对 InnoDB)。
3. Memory
内存引擎
数据存储在内存中,适合临时数据处理,性能极快但数据易失(重启丢失)。
5.7 版本特性
- 支持哈希索引(默认)和 B + 树索引,哈希索引适合等值查询(=),不支持范围查询(>、<)。
- 表大小受
max_heap_table_size限制(默认 16MB),超出后会报错。
8.0 版本改进
- 优化内存分配机制,减少小表的内存浪费。
- 支持动态调整
max_heap_table_size(无需重建表),更灵活适配临时数据大小。
4. CSV
逗号分割值引擎
数据以 CSV 格式文件存储(.csv),适合数据交换(如与 Excel、文本文件交互)。
5.7 版本特性
- 表结构存于
.frm文件,数据存于.csv文件,可直接用文本编辑器查看 / 修改。 - 不支持索引和事务,仅适合简单的导入导出场景。
8.0 版本改进
- 增强兼容性:支持 CSV 文件中包含换行符(需特殊处理),减少导入导出时的格式错误。
5. 总结
- InnoDB:5.7 已具备事务、行锁核心能力,8.0 通过自增 ID 持久化、索引优化、锁细化等提升可靠性和性能,是所有业务的首选。
- MyISAM:仅适合只读、低并发场景,8.0 中进一步被边缘化。
- Memory/CSV:作为辅助引擎,8.0 主要优化了易用性(如动态调整内存表大小),核心功能无本质变化。
04. InnoDB存储引擎
InnoDB作为MySQL的默认且常用的搜索引擎,有如下的核心特性:
1. 事务支持(ACID)
- 完全支持事务的原子性(A)、一致性(C)、隔离性(I)、持久性(D)。
2. 锁机制
- 支持行级锁 + 间隙锁(Next-Key Lock),行级锁仅锁定修改行(高并发友好),间隙锁防止幻读。
- 8.0 变化:间隙锁范围更精准,减少非必要锁定(如批量插入相邻 ID 时仅锁实际区间),降低锁冲突概率。
3. 聚簇索引
- 数据与主键索引物理存储在一起,形成 B + 树结构,主键查询可直接获取数据。
4. 自增 ID(AUTO_INCREMENT)
- 自增 ID 存储在内存中,MySQL 重启后可能因未持久化导致序列重复(需依赖 binlog 部分恢复)。
- 8.0 变化:自增 ID 写入 redo log 持久化,重启后可通过日志恢复序列,彻底解决重复问题。
5. 索引特性
- 支持 B + 树索引(默认)、全文索引、前缀索引;仅语法支持降序索引(
DESC),实际仍按升序存储。 - 8.0 变化:
- 真正支持降序索引,查询降序排序数据时无需额外排序,直接复用索引。
- 新增隐藏索引(
INVISIBLE),可临时禁用索引(不删除),方便测试索引性能影响。
6. 日志依赖(redo log/undo log)
- redo log:循环写的物理日志,记录数据页修改,保证崩溃恢复。
- undo log:记录数据修改前的状态,用于事务回滚和 MVCC(多版本并发控制),默认随表空间存储,易膨胀需手动清理。
- 8.0 变化:
- redo log 默认单个文件大小从 48MB 增至 1GB,减少日志切换开销。
- undo log 支持自动回收(
innodb_undo_log_truncate默认开启),无需手动清理。
7. 外键约束
- 支持表间外键关联(如:
orders.user_id关联users.id),保证数据引用完整性。
8. 安全性增强
- 无表空间加密功能,数据文件(
.ibd)以明文存储。 - 8.0 变化:新增透明数据加密(TDE),支持表空间文件加密存储,提升敏感数据安全性(如用户密码、支付信息表)。
05. 三大范式和反范式
MySQL 的三大范式(1NF、2NF、3NF)是关系型数据库设计的基础原则,目的是减少数据冗余、保证数据一致性、避免插入 / 更新 / 删除异常;
反范式是有意打破范式规则,有策略地保留适量冗余,目的是减少多表 JOIN,提升查询效率(尤其读多写少场景)。
1. 第一范式(1NF)
第一范式(1NF):字段原子化,不可再分。
- 核心要求:表中所有字段的值必须是 “原子性” 的(不可再拆分为更小的数据单元)。
- 目的:避免同一字段存储多维度信息,导致查询和修改混乱。
- 例子:
- 反例:用户表的
address字段存储 “中国 – 北京 – 朝阳区”(可拆分为country、city、district); - 正例:拆分为
country、city、district三个字段,每个字段不可再分。
- 反例:用户表的
- 实践:1NF 是基础,几乎所有业务表都需满足(如:订单表的
phone字段不存储 “固话 + 手机”,而是单独字段)。
2. 第二范式(2NF)
第二范式(2NF):消除 “部分依赖”,非主属性完全依赖主键。
- 核心要求:在 1NF 基础上,表的主键必须是 “联合主键”(多字段组成),且所有非主属性必须完全依赖于整个主键,不能仅依赖主键的一部分(即消除 “部分依赖”)。
- 目的:避免因主键部分字段变化导致的数据异常(如修改部分主键后,非主属性需联动更新)。
- 例子:
- 反例:订单项表(联合主键
order_id+product_id)中,product_name仅依赖product_id(主键的一部分),属于部分依赖; - 正例:
product_name应存储在产品表中,订单项表只存product_id,通过关联产品表获取名称(非主属性quantity、price完全依赖order_id+product_id)。
- 反例:订单项表(联合主键
- 实践:多对多关系的中间表(如 “用户 – 角色” 关联表)需满足 2NF,避免冗余存储角色名称等信息。
3. 第三范式(3NF)
第三范式(3NF):消除 “传递依赖”,非主属性不依赖其他非主属性。
- 核心要求:在 2NF 基础上,所有非主属性必须直接依赖于主键,不能依赖于其他非主属性(即消除 “传递依赖”)。
- 目的:避免因某个非主属性变化,导致其他非主属性需联动更新(如 A 依赖主键,B 依赖 A,则 B 传递依赖主键)。
- 例子:
- 反例:用户表(主键
user_id)中,area_name依赖area_id,area_id依赖user_id,则area_name传递依赖user_id; - 正例:
area_name应存储在区域表中,用户表只存area_id,通过关联区域表获取名称(非主属性仅直接依赖user_id)。
- 反例:用户表(主键
- 实践:用户表、商品表等核心表需满足 3NF,避免存储 “部门名称”“分类名称” 等可通过关联获取的字段。
4. 反范式
反范式是有意打破范式规则,有策略地保留适量冗余,目的是减少多表 JOIN,提升查询效率(尤其读多写少场景)。
- 核心思路
通过在表中冗余存储其他表的字段,避免查询时关联多个表(JOIN操作耗时,尤其大数据量时)。 - 例子:
- 电商商品列表页需展示 “商品名称 + 分类名称”,若严格遵循 3NF,需关联
product表和category表; - 反范式优化:在
product表中冗余category_name字段,查询时直接从product表获取,无需 JOIN。
- 电商商品列表页需展示 “商品名称 + 分类名称”,若严格遵循 3NF,需关联
- 适用场景
- 高频查询、低频更新:如商品详情页(查询频繁,分类名称很少修改),冗余后查询性能提升 10 倍以上;
- 多表关联复杂:如订单列表需关联用户表、商品表、物流表,冗余 “用户名”“商品名” 后,查询从多表 JOIN 简化为单表查询;
- 统计分析场景:报表系统需聚合多维度数据,冗余存储聚合结果(如 “每月销售额”),避免实时计算。
- 注意事项
- 冗余字段需同步更新:如
category_name修改后,需同步更新product表中的冗余字段(可通过触发器、Java 代码事务保证); - 控制冗余范围:只冗余高频查询的核心字段(如名称、状态),避免表过大(如冗余大文本字段会增加存储和 IO 成本)。
- 冗余字段需同步更新:如
5. 总结
- 范式:适合写多读少、数据一致性要求高的场景(如订单系统、用户中心),通过减少冗余降低更新异常风险;
- 反范式:适合读多写少、查询性能敏感的场景(如电商列表、报表),通过可控冗余提升查询效率。
- 实际开发中,很少严格遵循某一范式,而是混合使用(如核心交易表用 3NF 保证一致性,查询表用反范式提升性能)。
06. DDL、DML、DCL、DQL
MySQL 中 DDL、DML、DCL、DQL 是按操作类型划分的四大类 SQL 语言,分别对应:
- DDL:数据库结构定义;
- DML:数据操纵;
- DCL:权限控制;
- DQL:数据查询。
1. DQL:数据查询语言
Data Query Language。
- 定义:用于从数据库中查询数据,不修改数据或结构,是业务系统中最频繁的操作。
- 核心命令:
SELECT(含WHERE、JOIN、GROUP BY、ORDER BY、LIMIT等子句)。 - 作用:从表中提取所需数据,支撑业务展示(如列表页、详情页)、统计分析(如报表)等场景。
- 实践要点:
- 是 Java 开发中最常用的 SQL(如查询用户信息、订单列表),需结合索引优化(如
WHERE条件加索引、避免SELECT *); - 复杂查询(多表关联、聚合)需用
EXPLAIN分析执行计划,避免全表扫描或文件排序。
- 是 Java 开发中最常用的 SQL(如查询用户信息、订单列表),需结合索引优化(如
2. DML:数据操纵语言
Data Manipulation Language。
- 定义:用于修改表中的数据(增、删、改),会改变数据内容,但不改变表结构。
- 核心命令:
INSERT(新增);UPDATE(修改);DELETE(删除)。
- 作用:处理业务数据的生命周期(如创建订单、更新状态、删除无效记录)。
- 实践要点:
- 操作会触发事务(默认自动提交,可通过
BEGIN手动控制),需保证原子性(如订单创建时同时扣减库存,失败则回滚); - 批量操作优化:
INSERT用VALUES (),(),()批量插入(比单条循环高效),DELETE/UPDATE避免全表操作(加WHERE条件,如DELETE FROM log WHERE create_time < '2024-01-01'); - 高频写入场景(如日志)需控制频率,避免锁表影响查询。
- 操作会触发事务(默认自动提交,可通过
3. DDL:数据定义语言
Data Definition Language。
- 定义:用于定义或修改数据库、表、索引等结构,会改变数据库的元数据(结构信息)。
- 核心命令:
CREATE(创建,如CREATE TABLE、CREATE INDEX);ALTER(修改,如ALTER TABLE ADD COLUMN);DROP(删除,如DROP TABLE);TRUNCATE(清空表)。
- 作用:初始化数据库结构(如建表、加字段)、调整表结构(如新增索引、扩展字段)。
- 实践要点:
- 执行时可能锁表(尤其
ALTER TABLE在 InnoDB 中,大表修改会阻塞读写),生产环境需在低峰期执行,大表建议用在线 DDL 工具(如 pt-online-schema-change); - 谨慎使用
DROP和TRUNCATE(不可逆,TRUNCATE会清空数据且不触发事务回滚); - 索引相关 DDL(
CREATE INDEX)需评估必要性(索引提升查询但降低写入性能)。
- 执行时可能锁表(尤其
4. DCL:数据控制语言
Data Control Language。
- 定义:用于管理数据库用户权限和事务控制,控制谁能操作数据、操作范围。
- 核心命令:`
- GRANT`(授予权限);
REVOKE(撤销权限);COMMIT(提交事务);ROLLBACK(回滚事务)。
- 作用:保障数据安全(如限制应用账号只能操作指定表)、控制事务一致性。
- 实践要点:
- 权限遵循 “最小原则”:应用程序账号只授予
SELECT/INSERT/UPDATE等必要权限,禁止DROP/GRANT等高风险权限,避免用 root 账号直接连接业务系统; - 事务控制(
COMMIT/ROLLBACK)需在 Java 代码中配合业务逻辑(如分布式事务场景,确保多库操作一致性)。
- 权限遵循 “最小原则”:应用程序账号只授予
5. 总结
四类语言分工明确:
- DQL:查数据(业务展示核心);
- DML:改数据(业务操作核心);
- DDL:改结构(架构维护核心);
- DCL:控权限(安全保障核心)。
07. 数据库表字段类型
1. 核心字段类型及适用场景
1. 数值型:适合存储数字(整数、小数)
| 类型 | 特点(长度 / 范围) | JDK8对应类型 | 适用场景 |
|---|---|---|---|
TINYINT |
1 字节,范围 – 128 ~ 127 (无符号 0 ~ 255) |
Byte |
状态标识(如status:0 – 禁用、1 – 正常)、性别(0 – 女、1 – 男) |
INT |
4 字节,范围 – 21 亿 ~ 21 亿 | Integer |
普通 ID(如user_id、order_id,中小规模业务足够)、数量(如count) |
BIGINT |
8 字节,范围 ±9e18, 大约±90亿亿 |
Long |
大整数 ID(如分布式 ID、雪花 ID)、 高频增长数据(如万亿级订单量) |
DECIMAL(M,D) |
高精度小数 (M 总长度,D 小数位) |
java.math.BigDecimal |
金额(如amount:DECIMAL(10,2)表示最多 10 位,2 位小数)、利率 |
FLOAT/DOUBLE |
单 / 双精度浮点 (有精度损失) |
Float/Double |
非精确计算(如温度、重量,允许微小误差) |
2. 字符串型:适合存储文本
| 类型 | 特点(长度 / 范围) | JDK8对应类型 | 适用场景 |
|---|---|---|---|
CHAR(N) |
固定长度(N 字节,0 ~ 255), 空格填充 |
String |
长度固定的字符串(如手机号CHAR(11)、身份证号CHAR(18)) |
VARCHAR(N) |
可变长度(0 ~ 65535), 存储实际长度 |
String |
长度不固定的文本(如用户名VARCHAR(50)、地址VARCHAR(200)) |
TEXT |
大文本(最大 64KB) | String |
较长文本(如商品描述、用户备注,不适合建索引) |
MEDIUMTEXT/LONGTEXT |
更大文本(16MB/4GB) | String |
超大文本(如文章内容、日志详情,慎用,会拖慢查询) |
3. 日期时间型:适合存储时间
| 类型 | 特点(长度 / 范围) | JDK8对应类型 | 适用场景 |
|---|---|---|---|
DATETIME |
8 字节,范围 1000 ~ 9999 年, 无时区 |
java.time.LocalDateTime(不推荐 Date) |
业务时间(如订单创建时间create_time,不受服务器时区影响) |
TIMESTAMP |
4 字节,范围 1970 ~ 2038 年, 受时区影响 |
java.time.LocalDateTime(不推荐 Date) |
记录系统时间(如最后更新时间update_time,自动随时区转换) |
DATE |
3 字节,仅日期(年月日) | java.time.LocalDate(不推荐 Timestamp) |
生日、到期日(如birthday、expire_date) |
TIME |
3 字节,仅时间(时分秒) | java.time.LocalTime |
时段记录(如会议时长、打卡时间) |
4. 特殊类型:针对性场景
| 类型 | 特点(长度 / 范围) | JDK8对应类型 | 适用场景 |
|---|---|---|---|
ENUM |
枚举(存储整数,显示字符串) | String |
固定可选值(如pay_type:ENUM('WECHAT','ALIPAY','CARD')) |
SET |
集合(多选,最多 64 个值) | String |
多选项(如tags:SET('hot','new','discount')) |
BLOB |
二进制数据(如图片、文件) | byte[](字节数组) |
小型二进制(如头像缩略图,大型文件建议存 OSS,库中只存 URL) |
2. 经典面试点
1. 数值型:精度与范围陷阱
-
金额为什么用
DECIMAL而非FLOAT?
FLOAT是浮点型,存在精度损失(如0.1 + 0.2 = 0.300000004),而DECIMAL是精确小数,适合金额等强精度场景。 -
INT和BIGINT怎么选?
中小业务(千万级数据)用INT足够;分布式系统(如订单 ID 用雪花 ID,长度 18 位)必须用BIGINT,避免溢出。
2. 字符串型:长度与性能
-
CHAR和VARCHAR的核心区别?
CHAR固定长度,查询快但浪费空间(如手机号用CHAR(11)比VARCHAR(11)高效,无需计算长度);
VARCHAR节省空间,但查询需额外解析长度,适合长度波动大的场景(如地址)。 -
为什么不建议
VARCHAR(255)滥用?
MySQL 中VARCHAR(255)在某些引擎(如InnoDB)中会按 255 字节分配临时内存,即使实际数据很短,也会浪费内存(尤其排序、JOIN时),建议按实际需求设长度(如用户名VARCHAR(50))。 -
TEXT类型的坑?
TEXT字段不适合建索引(即使建索引也只能取前 N 个字符),且查询时会额外 IO,大文本建议拆分表(如商品表存desc_id,关联单独的product_desc表存TEXT内容)。
3. 日期时间型:时区与范围
-
DATETIME和TIMESTAMP怎么选?
业务时间(如订单创建时间)用DATETIME(固定值,不受服务器时区影响);系统时间(如最后修改时间)用TIMESTAMP(自动更新,适配多时区部署)。 -
TIMESTAMP的 2038 年问题?
因范围是 1970 ~ 2038 年,长期系统需注意(可改用DATETIME规避)。
4. 枚举类型ENUM的利弊
- 优点:存储高效(用整数存字符串),约束数据合法性(只能选定义的值);
- 缺点:修改枚举值需
ALTER TABLE(DDL 操作,大表阻塞),不适合值频繁变化的场景(如活动状态,建议用TINYINT+ 字典表替代)。
3. 总结
字段类型选择的核心原则:“够用即可,避免冗余”
- 数字优先选小类型(如状态用
TINYINT而非INT); - 字符串按长度固定与否选
CHAR/VARCHAR,避免大文本字段拖累主表; - 日期根据时区需求选
DATETIME/TIMESTAMP; - 金额、ID 等关键字段必须保证精度和范围,避免溢出或精度丢失。
回目录: 《面试笔记:MySQL 相关目录》
下一篇: 《面试笔记:MySQL 相关02 – 索引》
